使用systemtap调查异常io的来源
最近发现测试环境里有个怪现象:在没有任何外部请求的情况下,磁盘的使用率(%util)依然能够达到40%甚至更多。为了排查这个问题,我使用了SystemTap这个神器。使用前首先根据官网安装好所有的依赖。
现象
iostat的部分输出如下:
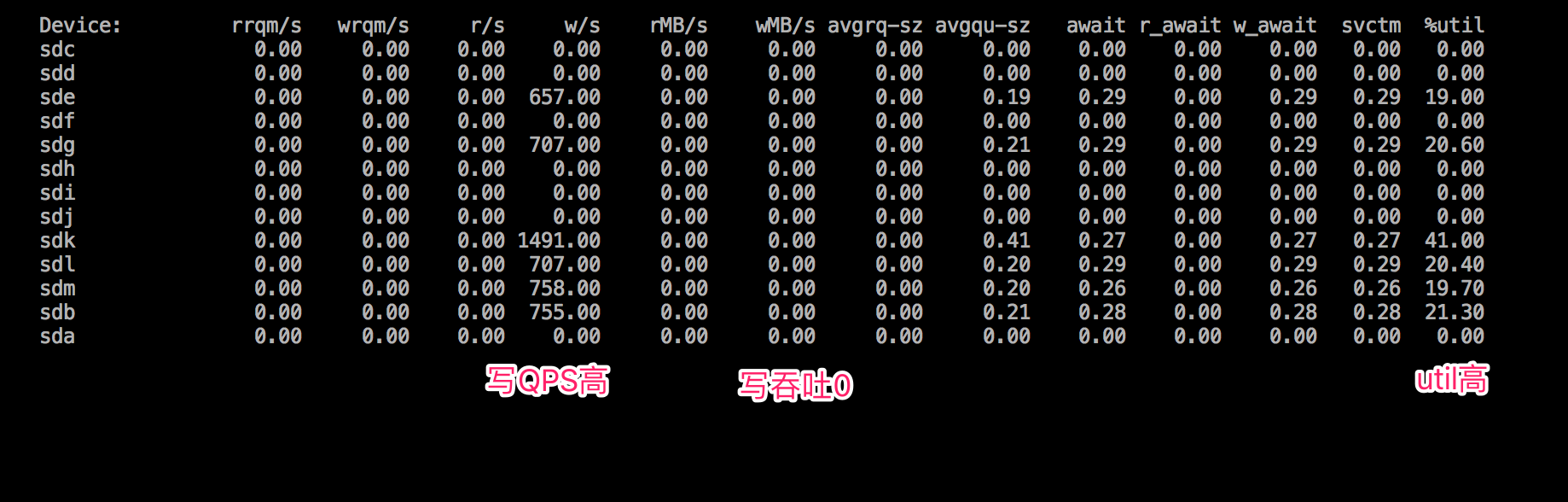{:height="294px" width="919px"}
可以看到磁盘写QPS高,但是却没有写入任何数据。现在我们需要定位出到底是哪个进程的哪部分代码造成了这个问题。
查看write、pwrite调用情况
第一个想法是看看有没有人在调用write或者pwrite。把SystemTap Beginner Guide中的iotime.stp修改一下,并更名为all-iotime.stp,用来把系统中所有调用上述两个系统调用的进程号等信息打印出来。因为我们会把结果输出到iotime.log,所以在脚本里把读写这个文件名的访问给过滤掉了。
#! /usr/bin/env stap
global start
function timestamp:long() { return gettimeofday_us() - start }
probe begin { start = gettimeofday_us() }
probe syscall.write.return,syscall.pwrite.return {
p = pid()
fd = @entry($fd)
file = @cast(task_current(), "task_struct")->files->fdt->fd[fd]
filename = __file_filename(file)
if (filename != "" && filename != "iotime.log") {
bytes = $return
time = gettimeofday_us() - @entry(gettimeofday_us())
printf("[%d] %d write fd=%d filename=%s bytes=%d time=%d\n", p, timestamp(), fd, filename, bytes, time)
}
}
运行:
# stap -DSTP_NO_OVERLOAD ./all-iotime.stp > iotime.log
这里如果不使用-DSTP_NO_OVERLOAD可能会出现如下错误:
ERROR: probe overhead exceeded threshold
WARNING: Number of errors: 1, skipped probes: 0
WARNING: /usr/bin/staprun exited with status: 1
Pass 5: run failed. [man error::pass5]
分析了输出结果,发现并没有大量的write或者pwrite调用。
bitesize-nd.stp定位问题进程
因为现象是有写入QPS,但是吞吐为0,所以有可能是某个进程一直在写0字节长度的数据。Brendan Gregg大神的bitesize-nd.stp这一SystemTap脚本正好可以统计进程的I/O大小分布。下载,运行:
# ./bitesize-nd.stp
Tracing block I/O... Hit Ctrl-C to end.
^C
I/O size (bytes):
process name: kworker/u113:1
value |-------------------------------------------------- count
1024 | 0
2048 | 0
4096 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 28
8192 |@@@ 3
16384 | 0
32768 | 0
...省略部分输出...
process name: java
value |-------------------------------------------------- count
0 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 74992
1 | 0
2 | 0
可以看到一个java进程在做大量的长度为0的I/O。我们可以稍微修改一下这个脚本就可以得到对应的进程号。我们的系统中就这么一个java进程在跑,可以轻易的定位到具体的进程。
定位系统调用
虽然知道是哪个进程出了问题,但还是不清楚哪个系统调用被频繁的调用。此时,如果我们在问题进程写磁盘路径上打印内核栈,就能知道是哪个调用链在写盘了。根据网上的例子,于是就有了下面名为iowrite-bt.stp的脚本:
#!/usr/bin/stap
global write_stacks
probe ioblock.request {
if(bio_rw_num(rw) == BIO_WRITE && devname == "sdd" && pid() == target()) {
write_stacks[backtrace()]++
}
}
probe end {
foreach (stack in write_stacks) {
printf("----------%d-------------\n", write_stacks[stack])
print_syms(stack)
}
delete write_stacks
}
这个脚本只会统计sdd这块盘上的磁盘写操作,根据调用栈进行次数统计,并最终打印出来。运行之:
# ./stap -d xfs -x 55157 iowrite-bt.stp
^C----------2830-------------
0xffffffff812c7130 : generic_make_request+0x0/0x130 [kernel]
0xffffffff812cd89b : blkdev_issue_flush+0xab/0x110 [kernel]
0xffffffffa056bdc9 : xfs_blkdev_issue_flush+0x19/0x20 [xfs]
0xffffffffa0555506 : xfs_file_fsync+0x1e6/0x200 [xfs]
0xffffffff8120f975 : do_fsync+0x65/0xa0 [kernel]
0x1 : ftrace_define_fields_xfs_attr_list_class+0x1/0x23a [xfs]
0xffffffff8120fc40 : SyS_fsync+0x10/0x20 [kernel]
0xffffffff81645909 : system_call_fastpath+0x16/0x1b [kernel]
其中
-d xfs表明把xfs模块的符号表也加载进来,既然sdd上的文件系统是XFS。-x 55157指定进程号,对应于脚本里target()的返回值。 可以看到问题进程一直在做fsync,而且推想是在文件根本没有改变的情况下频繁调用fsync。
到了这一步,我们再去查看代码,发现有个后台进程对大量的文件定时做flush,而不管文件是否被改变。
小结
早就知道有SystemTap这么一个全能工具,以前一直误以为它的安装和使用比较难。这次使用发现,只要对内核有一定的了解,直接用网上成熟的脚本或者加以一定的修改,就能获得非常好的效果。SystemTap是一个值得投入时间学习的系统分析利器。